RLChina
RLChina 是由国内外强化学习学者联合发起的民间学术组织,主要活动包括举办强化学习线上公开课、强化学习线上研讨会等,旨在搭建强化学习学术界、产业界和广大爱好者之间的桥梁。
评论(60)
请
登录后发表观点
- 请问李老师,您认为用强化学习代替传统的MPC PID等进行车辆的的操纵性或者稳定控制,这个方向可行性和意义如何呀?或者说效果怎么样?
感谢这位同学的提问,恭喜获赠书籍!RLChina 强化学习社区后续会送出,请在 9 月 15 日前发送您的社区昵称、注册邮箱、姓名、电话和寄送地址至官方邮箱 rlchinacamp@163.com
-
https://arxiv.org/pdf/2203.11405.pdf 这篇文章里对自动驾驶系统加入记忆的功能,从过去的经验中学习。人和机器系统有着很大的不同,比如人的记忆对不同的内容有不同的记忆精度,记忆激活时具有联想性 associative,并且存储具有表征的恒常性等,请问老师怎么看待自动驾驶结合(更像人)的记忆系统,这会是以后的趋势吗?
感谢这位同学的提问,恭喜获赠书籍!RLChina 强化学习社区后续会送出,请在 9 月 15 日前发送您的社区昵称、注册邮箱、姓名、电话和寄送地址至官方邮箱 rlchinacamp@163.com
-
请问李老师如何看待最优控制与 RL 的结合产物 ADP(adaptive/approximate dynamic programming)? ADP 有什么缺点吗?以后会成为主导趋势吗?
感谢这位同学的提问,恭喜获赠书籍!RLChina 强化学习社区后续会送出,请在 9 月 15 日前发送您的社区昵称、注册邮箱、姓名、电话和寄送地址至官方邮箱 rlchinacamp@163.com
-
-
https://arxiv.org/pdf/2203.11405.pdf 这篇文章里对自动驾驶系统加入记忆的功能,从过去的经验中学习。人和机器系统有着很大的不同,比如人的记忆对不同的内容有不同的记忆精度,记忆激活时具有联想性 associative,并且存储具有表征的恒常性等,请问老师怎么看待自动驾驶结合(更像人)的记忆系统,这会是以后的趋势吗?
感谢这位同学的提问,恭喜获赠书籍!RLChina 强化学习社区后续会送出,请在 9 月 15 日前发送您的社区昵称、注册邮箱、姓名、电话和寄送地址至官方邮箱 rlchinacamp@163.com
-
请问李老师如何看待最优控制与 RL 的结合产物 ADP(adaptive/approximate dynamic programming)? ADP 有什么缺点吗?以后会成为主导趋势吗?
感谢这位同学的提问,恭喜获赠书籍!RLChina 强化学习社区后续会送出,请在 9 月 15 日前发送您的社区昵称、注册邮箱、姓名、电话和寄送地址至官方邮箱 rlchinacamp@163.com
-

老师,我们是山东老乡,为何论文强化学习应用,一般不按直接法、间接法这样分类使用?
科研过程也存在路径依赖问题。早期研究对 RL 的理解不够充分,尤其是与最优控制的关联性。例如:上个世纪 60~70 年甚至认为 RL 就是探索试错学习,80 年代 R Sutton 等人的研究改变了这一观点,他们从 TD 研究出发,慢慢建立了与 DP 的联系。很多时候,后面的研究者一般会沿用开创者的思路,形成各式各样的路径依赖,包括分类方法。随着研究工作的深入,我们也会形成全新的理解观点,用于再解释早期的方法,或者创造全新的方法。看同一问题的角度不同了,通常就会产生全新的科研创意。对于间接法和直接法的解释,具体可参考:Y Guan, S Li*, et al. Direct and indirect reinforcement learning. International Journal of Intelligent Systems, 2021, https://doi.org/10.1002/int.22466
-
-
对于哈密尔顿系统,存在一类保辛离散化算法,可极大提升数值求解的稳定性,是冯康先生 80 年代的工作。
近年 UC Berkeley 的 MJ,将该思想用于解释优化问题的迭代过程,给我们的一个启发是:adam 算法从某种意义上是保辛优化算法的一个特例,这是它为什么这么稳定的理论解释。
-
-
-
-
请问老师,是不是间接法主要是 policy-based 方法,直接法主要是 value-based 方法。
这个理解是不准确的。间接法是指采用 Bellman equation,求解该方程的方法。间接法也可以 policy-based,也可以 value-based。例如,若是求解 Bellman equation 时,只对策略进行近似,而不对 value 进行近似(使用 MC 估计),就是 policy-based 的方法。若是采用 fixed-point iteration 对 Bellman equation 进行求解,就成为 value-based 方法,例如:结合 Mann fixed-point iteration 就是一个标准的 Q-learning 方法。所以,policy-based 和 value-based 分类法,是早期对强化学习理解不充分的一个产物,不能对 RL 的算法设计产生足够的指导意义。
-
-
-
-
-
-
感谢这位同学的提问,恭喜获赠书籍!RLChina 强化学习社区后续会送出,请发送您的姓名电话和寄送地址至官方邮箱 rlchinacamp@163.com
喵喵喵?难道不是今天一个被直播回答的问题是我的吗?
-
老师您好,请问您刚刚说的提高强化学习的稳定性,用的保新算法嘛,没太请听
-
老师好,我想问一下,强化学习的决策部分一般使用神经网络来拟合,但是神经网络能够训练完成后任务效果的上限是多少呢,换句话说,神经网络的模型能否完美的表示我们的决策这个真实模型吗?我们又应该如何选择这个网络模型的结构呢?
感谢这位同学的提问,恭喜获赠书籍!RLChina 强化学习社区后续会送出,请发送您的姓名电话和寄送地址至官方邮箱 rlchinacamp@163.com
- 请问用greedy search方法是不是只能得到pure strategy的解。对于一些最优解是mixed strategy的问题我们能用什么方法解呢
感谢这位同学的提问,恭喜获赠书籍!RLChina 强化学习社区后续会送出,请发送您的姓名电话和寄送地址至官方邮箱 rlchinacamp@163.com
-
老师好!想请问一下,是不是直接法主要是 policy-based 方法,间接法是 value-based 方法?
感谢这位同学的提问,恭喜获赠书籍!RLChina 强化学习社区后续会送出,请发送您的姓名电话和寄送地址至官方邮箱 rlchinacamp@163.com
-

现在到神经网络来源于图像识别等问题,这些神经网络直接用于强化学习存在哪些问题?有哪些研究的方向?
-
老师好,请问您怎么看待强化学习的因果性。RL 可否带上一写 casuality 的因素来进一步探索动作与状态之间的联系,以建立更好的控制器。
-
老师好。在课上介绍 baseline 方法的时候,你说 baseline 和 TD 在某种意义上等价。在昨天的课,老师介绍过 TD 方法是有偏的。然而据我所知,baseline 方法是对 policy gradient 的无偏估计。请问这边是不是有点问题?
-
提问:请问当前在 RL 的实践领域,multi agent 场景下的应用是否很困难,针对这些困难有哪些解决思路?
-
老师您好,我想请问下,将基于数据驱动的方法和基于模型的方法相结合,有哪些优势,可以应用于解决哪些问题呢?
-
老师您好,请问 RL 用于图像优化并对其进行进行分类吗,从理论角度讲可行吗?有可能提高准确率吗?
-
老师,我们是山东老乡,为何论文强化学习应用,一般不按直接法、间接法这样分类使用?
-
老师您好,我想请问一下,直接法是经过一步步简化得来的,那我们是否可以未来一步步释放简化去针对问题得到更好的结果呢?
- 老师,在车联网方面,rl是否可以用于车辆间的组网呢,不同时间段的车流量的差别是否可以理解为环境的变化呢
-
提问:请问老师例子中,stochastic Q; stochastic V; Determinstic Q; 中,stochastic 和 Determinstic 分别是指在策略近似中用的模板策略用的分别是什么呢?
-
老师您好,针对连续状态训练效果差的情况下,很多参考做法是将连续空间换成多值离散空间。如果在自动驾驶或控制领域上来说,这样做是否可行?是否会损失一部分的安全性?
-
请问分析 RL 控制效果的瞬态性能有哪些方法?
-
老师您好,请问您提到的给 RL 系统增加滤波的设计,如果是无模型的算法,那这种滤波机制是在状态输入的地方好一点还是动作选择的地方好一点?(ps.不知道我是不是理解偏了)
-
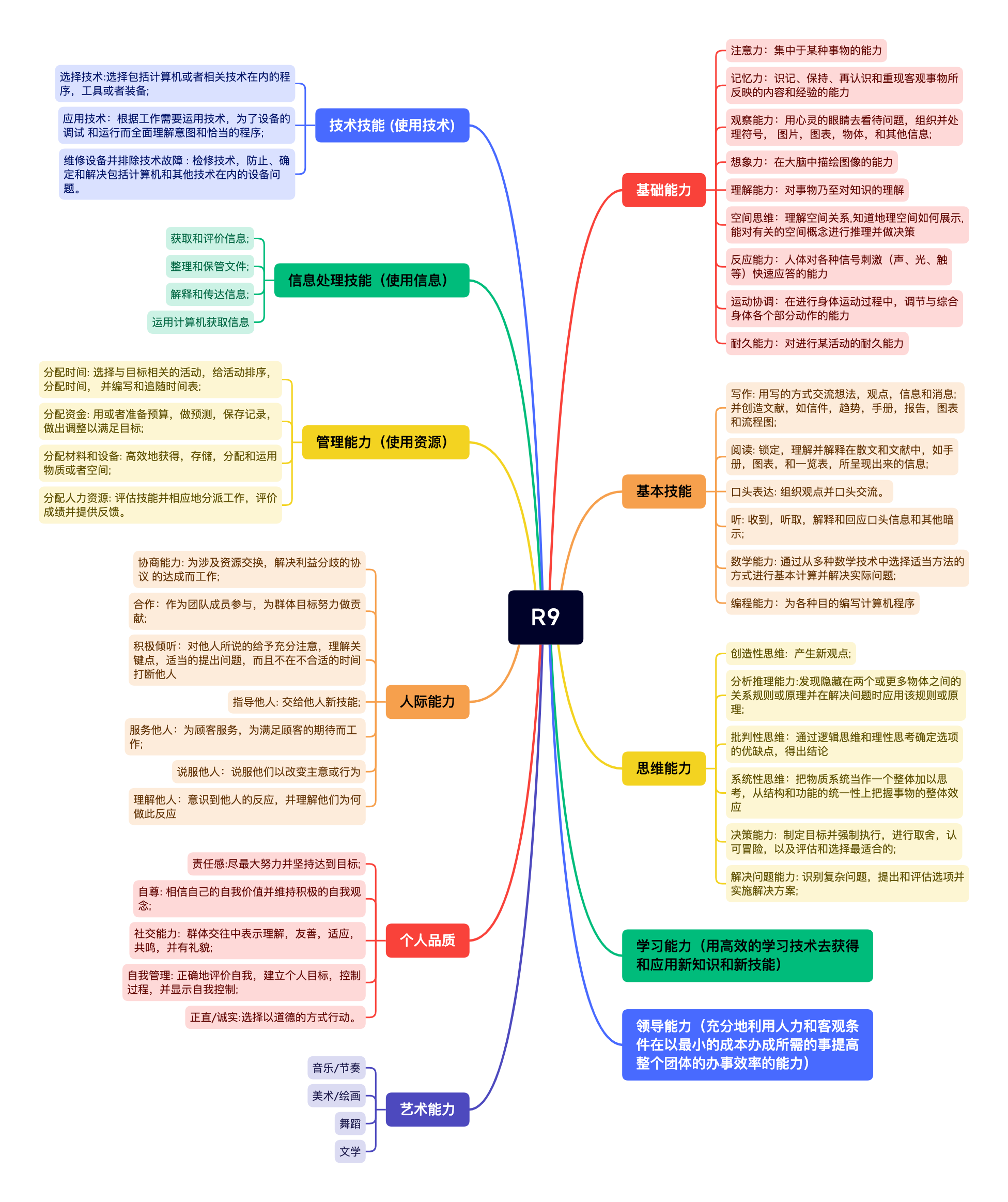
老师好!想请问一下,是不是直接法主要是 policy-based 方法,间接法是 value-based 方法?
-
请问老师,间接法对比直接法只是收敛效率上的提升吗,最终模型的性能有何差别?
- 请问用greedy search方法是不是只能得到pure strategy的解。对于一些最优解是mixed strategy的问题我们能用什么方法解呢
-
老师好,我想问一下,强化学习的决策部分一般使用神经网络来拟合,但是神经网络能够训练完成后任务效果的上限是多少呢,换句话说,神经网络的模型能否完美的表示我们的决策这个真实模型吗?我们又应该如何选择这个网络模型的结构呢?
-
提问:在 AI 领域和在 Game Theory 领域,learning 有着不同含义,AI 注重 performance 的提升,Game Theory 注重 equilibrium 的分析,请问在当前的研究中,这两种范式是否有某些融合趋势? 或者说,哪一种范式在学界/业内更受青睐?
-
请问老师,像自动驾驶这种没有明显回报的过程,如何设置模型的环境和回报?
-
集成式决策控制和他对 RL 使用的影响能请老师细介绍下吗,
- 请问李老师,您认为用强化学习代替传统的MPC PID等进行车辆的的操纵性或者稳定控制,这个方向可行性和意义如何呀?或者说效果怎么样?
-
请问老师,是不是间接法主要是 policy-based 方法,直接法主要是 value-based 方法。
-
RL 中的 MPC 和单纯的 MPC 是同样的方法吗?它们有什么区别和联系?
-
老师您好,请问讲强化学习和最优控制相结合是否可以看作是某种意义上的可解释性强化学习?
-
请问老师您觉得在机械臂控制方面,强化学习有什么好的应用前景或者方向吗?
-
请问老师,Model-free 和 Model-base 的本质性区别在哪里,有没有什么直观的判断方法?