RLChina
RLChina 是由国内外强化学习学者联合发起的民间学术组织,主要活动包括举办强化学习线上公开课、强化学习线上研讨会等,旨在搭建强化学习学术界、产业界和广大爱好者之间的桥梁。
评论(35)
请
登录后发表观点
-
请问田老师 n-step 操作是否就是在 MC 和 TD 两种方法的折中,相应的在 variance 和 bias 两者取一个 tradeoff?另外经过本人亲身实践,强化学习训练过程中的 return 很难收敛,请问该用什么方式来判断收敛呢?
感谢这位同学的提问,恭喜获赠书籍!RLChina 强化学习社区后续会送出,请在 9 月 15 日前发送您的社区昵称、注册邮箱、姓名、电话和寄送地址至官方邮箱 rlchinacamp@163.com
-
怎么评价 RL 算法在一个模型比如游戏上的性能呢?算法的收敛性怎么体现呢?除了累计的 rewars 随 episodes 逐渐平稳,有没有类似 loss 这种指标呢?
感谢这位同学的提问,恭喜获赠书籍!RLChina 强化学习社区后续会送出,请在 9 月 15 日前发送您的社区昵称、注册邮箱、姓名、电话和寄送地址至官方邮箱 rlchinacamp@163.com
-
请问下,爬楼梯那种问题里 DP 算法只用状态转移遍历一遍所有 state,就可以了。 而今天介绍的值迭代和策略迭代要不断更新,是因为考虑的场景里有随机性吗?
感谢这位同学的提问,恭喜获赠书籍!RLChina 强化学习社区后续会送出,请在 9 月 15 日前发送您的社区昵称、注册邮箱、姓名、电话和寄送地址至官方邮箱 rlchinacamp@163.com
-
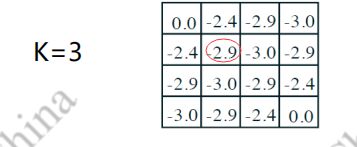
这个-2.9 是怎么计算出来的? -
请问田老师 n-step 操作是否就是在 MC 和 TD 两种方法的折中,相应的在 variance 和 bias 两者取一个 tradeoff?另外经过本人亲身实践,强化学习训练过程中的 return 很难收敛,请问该用什么方式来判断收敛呢?
感谢这位同学的提问,恭喜获赠书籍!RLChina 强化学习社区后续会送出,请发送您的姓名电话和寄送地址至官方邮箱 rlchinacamp@163.com
-
怎么评价 RL 算法在一个模型比如游戏上的性能呢?算法的收敛性怎么体现呢?除了累计的 rewars 随 episodes 逐渐平稳,有没有类似 loss 这种指标呢?
感谢这位同学的提问,恭喜获赠书籍!RLChina 强化学习社区后续会送出,请发送您的姓名电话和寄送地址至官方邮箱 rlchinacamp@163.com
-
请问下,爬楼梯那种问题里 DP 算法只用状态转移遍历一遍所有 state,就可以了。 而今天介绍的值迭代和策略迭代要不断更新,是因为考虑的场景里有随机性吗?
感谢这位同学的提问,恭喜获赠书籍!RLChina 强化学习社区后续会送出,请发送您的姓名电话和寄送地址至官方邮箱 rlchinacamp@163.com
-
可以区分一下 leanring/planning/prediction/control 四个概念吗
-
请问 REINFORCE 什么情况下能收敛到全局最优?
-

田老师,您好,我想问下,dqn 中网络层数和节点数有什么设计方法?replay buff 和 batchsize 是越大越好么?
-
老师您好,您讲解的非常好,非常深入浅出。想请教老师,DQN 算法除了对于连续环境有优势外,相比于 q-learning 算法有什么更大的优势呢?
-
请问老师:
DRL model-based 算法的 eval_return 本来很高后来突然降到很低然后持续这个很低的值应该是什么原因,建议怎么处理?这个“很低”甚至是 0 且一致保持是 0 应该怎么办?
一个算法的 performance 达到多少才被公认为“正确解决”了这个 rl 环境?
bootstrap 概念上是什么意思?
DRL 算法跑了很长时间一直不收敛应该怎么处理?batch_size, episodes 的数目和 max_epoch 的值应该怎么设置?
譬如股票价格作为状态,之前学习时遇到的状态一般不会在之后还能遇到,这样之前学到的 DRL 算法还能有用吗?
对于 DRL 的优化器,根据经验讲,一般使用 Adam 和其他如 sgd,momentum 等会有很大区别吗?
谢谢老师! -
DynaQ 算法学习的模型是确定性环境模型,那如果想用之前未出现过的状态和动作来更新 Q 的话,是不是就只能跟环境去交互而不能使用学习到的模型了?
- 请问老师dyna和DQN都有存着过去的过程,他们的区别是什么
-
老师您好,在实际过程中对不同强化学习方法进行训练的时候,我们如何能判断当前训练效果不理想是由于算法本身能力不足所导致的,还是由于超参数设置不合理导致的。针对于环境模型的学习,我们如何判断对于环境学习所收集的数据是充足的。
关于实际算法训练的技巧方面想请教一下,谢谢。 -
请问田老师 n-step 操作是否就是在 MC 和 TD 两种方法的折中,相应的在 variance 和 bias 两者取一个 tradeoff?另外经过本人亲身实践,强化学习训练过程中的 return 很难收敛,请问该用什么方式来判断收敛呢?
-
dyna-q 里的 model 也可以用神经网络吗
-
老师您好,在实际过程中对不同强化学习方法进行训练的时候,我们如何能判断当前训练效果不理想是由于算法本身能力不足所导致的,还是由于超参数设置不合理导致的。关于实际算法训练的技巧方面想请教一下,谢谢。
-
老师,自己搭建的场景奖励函数设置有什么技巧吗,奖励函数会影响收敛性吗,为什么有时候稠密奖励的效果不如稀疏奖励呢?谢谢老师
- 老师请问一下,如果训练时reward不收敛的话,具体可能是什么原因,可以依次从哪些方面对算法进行调整(如:奖励函数,模型等等),检查的顺序是怎样的。
-
Qlearning 中的策略函数取 max 和 sarsa 算法中的 greedy 策略有啥不同吗
-
在使用 Experience replay 的时候想使用 TD(n)的算法时候 储存的是时间序列么 这种经验的存取要如何进行?
-
Sarsa+epsilon 退火能接近最优,能不能理解为 sarsa 是 on-policy 的方法,估计的就是 epsilon-greedy 策略的 value,因此始终和 optimal 策略有差异,但是当 epsilon 退火到接近于 0 时,这时 sarse 就在逐渐逼近到了最优策略
-
怎么评价 RL 算法在一个模型比如游戏上的性能呢?算法的收敛性怎么体现呢?除了累计的 rewars 随 episodes 逐渐平稳,有没有类似 loss 这种指标呢?
投稿论文的时候有评委提意见说给使用的 RL 算法说明收敛性,以及算法的复杂性分析,不知道除了能够找到任务的近似解,returns 逐渐收敛这种方式外还可以从哪个方面说明算法训练收敛了。。
-
怎么评价 RL 算法在一个模型比如游戏上的性能呢?算法的收敛性怎么体现呢?除了累计的 rewars 随 episodes 逐渐平稳,有没有类似 loss 这种指标呢?
-
如果以移动平均理解目标的更新,那怎么理解 alpha,学习率是相当于对目标的估计的信任程度吗?
-
请问下,爬楼梯那种问题里 DP 算法只用状态转移遍历一遍所有 state,就可以了。 而今天介绍的值迭代和策略迭代要不断更新,是因为考虑的场景里有随机性吗?
- 请问老师,在RL算法的应用中,动作空间的分层设计该如何合理进行高层动作与底层动作的分配及设计。还有如何克服动作屏蔽机制所导致的探索效率低这一问题呢。谢谢老师。
-
请问老师 Policy based 和 Value Based 的强化学习对比下来各有什么样的优缺点,Policy based,Value Based 和 Actor Critic 分别适用于哪些场景呢?
-
Planning 跟 Learning 最大的区别是什么?
-
对于 Q 和 V 的定义,看圣经是用的动态特性 P(s',r|s,a)而不是转移方程 P(s'|s,a),请问这种与动手学强化学习里的定义有啥区别吗?