RLChina
RLChina 是由国内外强化学习学者联合发起的民间学术组织,主要活动包括举办强化学习线上公开课、强化学习线上研讨会等,旨在搭建强化学习学术界、产业界和广大爱好者之间的桥梁。
评论(55)
请
登录后发表观点
-
张老师好,个人感觉 actor-critic 算法和 GAN 的结构(generator 和 discriminator)很类似。请问二者的区别和联系在什么地方?
感谢这位同学的提问,恭喜获赠书籍!RLChina 强化学习社区后续会送出,请在 9 月 15 日前发送您的社区昵称、注册邮箱、姓名、电话和寄送地址至官方邮箱 rlchinacamp@163.com
-
老师您好,我是一名博士研究生。我心中一直有个怀疑,感觉其实强化学习与监督学习的本质其实都是一样的,只是一个使用奖励来引导学习(虽然交互的数据的分布式变化的,但是环境模型是人给定的,奖励也是人为定义的),一个使用 label 来引导学习。这样做的结果就是强化学习的搜索空间会大很多,但只要算力足够了仍然可以收敛。我想这就是为什么腾讯绝悟,alphastar 等等能用强化学习收敛的直接原因。现在很多言论说 RL 是通向 AGI 的道路,但是是否这样做的话,那么奖励、环境模型的设计事实上比算法模型更加有效,最近看到 deepmind 发的 reward is enough 就很有共鸣,想问问老师对两种学习的本质区别的看法,谢谢老师!
感谢这位同学的提问,恭喜获赠书籍!RLChina 强化学习社区后续会送出,请在 9 月 15 日前发送您的社区昵称、注册邮箱、姓名、电话和寄送地址至官方邮箱 rlchinacamp@163.com
-
今年的课会和去年一样嘛?
感谢这位同学的提问,恭喜获赠书籍!RLChina 强化学习社区后续会送出,请在 9 月 15 日前发送您的社区昵称、注册邮箱、姓名、电话和寄送地址至官方邮箱 rlchinacamp@163.com
-
张老师好,个人感觉 actor-critic 算法和 GAN 的结构(generator 和 discriminator)很类似。请问二者的区别和联系在什么地方?
感谢这位同学的提问,恭喜获赠书籍!RLChina 强化学习社区后续会送出,请发送您的姓名电话和寄送地址至官方邮箱 rlchinacamp@163.com
-
老师您好,我是一名博士研究生。我对这个 MDP 的结构有个疑问。
1、在选择动作 a 之后是先转移到 S 还是先获得奖励 R 呢,还是说这个不重要?但可能会影响到一个 episode 结束时获得是否要累计最后状态的获得的奖励。感谢这位同学的提问,恭喜获赠书籍!RLChina 强化学习社区后续会送出,请发送您的姓名电话和寄送地址至官方邮箱 rlchinacamp@163.com
-
老师好,我是电子科技大学的研一学生,研究方向为强化学习和联邦学习(博弈论视角)。非常荣幸能听到老师这次讲座。在这里我有两个个人认为比较有价值的问题想请教一下老师。
第一:众所周知,强化学习由于其和环境交互的激励机制,与我们人类大脑的奖惩机制有一些异曲同工之处,以强化学习之父 Richard Sutton 为代表的一众学者也认为强化学习是我们通往通用人工智能 AGI 的一条路径,而 DeepMind 公司的一些科研工作例如 AlphaGO 也在实践上将这一理念在一定程度上变成了现实。另外值得一提的是,当前也有一部分学者在做将强化学习和一些演化计算等基于生物智能的方法结合的研究工作。所以,我想请教一下老师您如何看待“强化学习通往 AGI”这一路径,是否值得探索?以及如果可行的话,您又认为强化学习和类脑计算以及演化计算等生物智能的方式结合能擦出什么样的火花?
第二:当前很多强化学习的工作方式还局限在例如游戏 AI 等情景的封闭环境当中,在很多开放环境下还不是特别适用,而南京大学的俞扬教授等学者也认为强化学习当前最大的阻碍是落地难的问题,所我想请教一下老师强化学习破解这一瓶颈有哪些值得探索的方式?
再次感谢老师。感谢这位同学的提问,恭喜获赠书籍!RLChina 强化学习社区后续会送出,请发送您的姓名电话和寄送地址至官方邮箱 rlchinacamp@163.com
- 请问有没有课程回放呢?
-
老师您好!强化学习比如 Q-learning 算法如何平衡探索与开发?有什么好的方法?或者需要考虑那些方面
-
请问老师,POMDP 如何在强化学习中建模
-
老师您好,感谢您的分享,我有几个问题:
- 如果说 RL 和监督学习的核心区别是数据分布不同,那么 Offline-RL 和监督学习的区别是什么?
- 深度强化学习中,神经网络也只是近似一个当前的策略价值,相较于 Q 学习的估计优势在哪里?主要 motivation 是状态空间和动作空间太大,导致 Q 函数无法储存,于是使用神经网络来近似吗?
-
A2C 和普通的 actor-critic 相比有什么优势吗?
-
老师你好,想请问下目前有没有比神经网络更好参数化值函数的方法?
-
老师您好,请问提升强化学习的收敛速度有什么比较好的方式?
-
张老师好,个人感觉 actor-critic 算法和 GAN 的结构(generator 和 discriminator)很类似。请问二者的区别和联系在什么地方?
-
张老师您好,十分有幸能聆听您的课程讲解,我是广西科技大学的一名计算机硕士研究生,想咨询一下您,在城市交通流预测或者是交通信号控制问题中,环境是不是都是非稳定的?正在拜读您的上交学生一些结合深度强化学习的交通领域论文,您觉得在这个领域里有哪些难点和方向还有待解决的?十分感谢您的解答和讲解~
-
老师好,在强化学习训练方面,可以设计辅助神经网络来加快训练,高估问题,怎么处理?谢谢。
-
伟楠老师讲得太好了!!!!
- 请问张老师对于目前对于强化学习在机器人、自动驾驶、推荐系统等领域落地的看法?offline rl是否是让rl落地正确的方向?对于常用的actor critic算法,张老师觉得核心是actor还是critic呢,哪一方发挥了更大的作用(一个比较主观的问题)?
-
老师您好?强化学习如何平衡探索与开发?有什么好的方法?或者需要考虑那些方面
-
老师您好?强化学习如何平衡探索与平衡?有什么好的方法?或者需要考虑那些方面?
- 关于强化学习中的奖励政策设置老师有没有比较好的方法或者理论可以推荐?有的时候奖励设置不好的话,学习过程会陷入无解状态(比如奖励有正负之分的情况下,学习过程会不会陷入假的最优策略中)
-
老师好,请问一下 R(s,a)究竟是 s 状态时获得的奖励,还是 s 状态做了 a 动作后获得的奖励,还是 s 状态做了 a 动作后到达 s'获得的奖励?还是说这个不重要?但可能会影响到一个 episode 结束时获得是否要累计最后状态的获得的奖励。
- 还有一个问题想请教老师,就是我如何将强化学习与车辆控制进行更好的结合应用,老师有没有好的方法或者点进行推荐呢?
- 强化学习的理论部分是这些,请问老师关于强化学习算法是多样的,比如DDPG DQN QLearning、SARSA,SAC等等,那这些多样化的算法核心区别是什么?在实际应用中只能采用这些算法吗?
-
强化学习中,如果 model 已有就是规划问题,那学习体现在学习 model 吗?如果用 model free 的方法,学习体现在学习 V 或者 Q,是这样理解吗?
-
常用的 on-policy 算法有哪些
-
老师好,我想问一下,强化学习的决策部分一般使用神经网络来拟合,但是神经网络能够训练完成后任务效果的上限是多少呢,换句话说,神经网络的模型能否完美的表示我们的决策这个真实模型吗?我们又应该如何选择这个网络模型的结构呢?
-
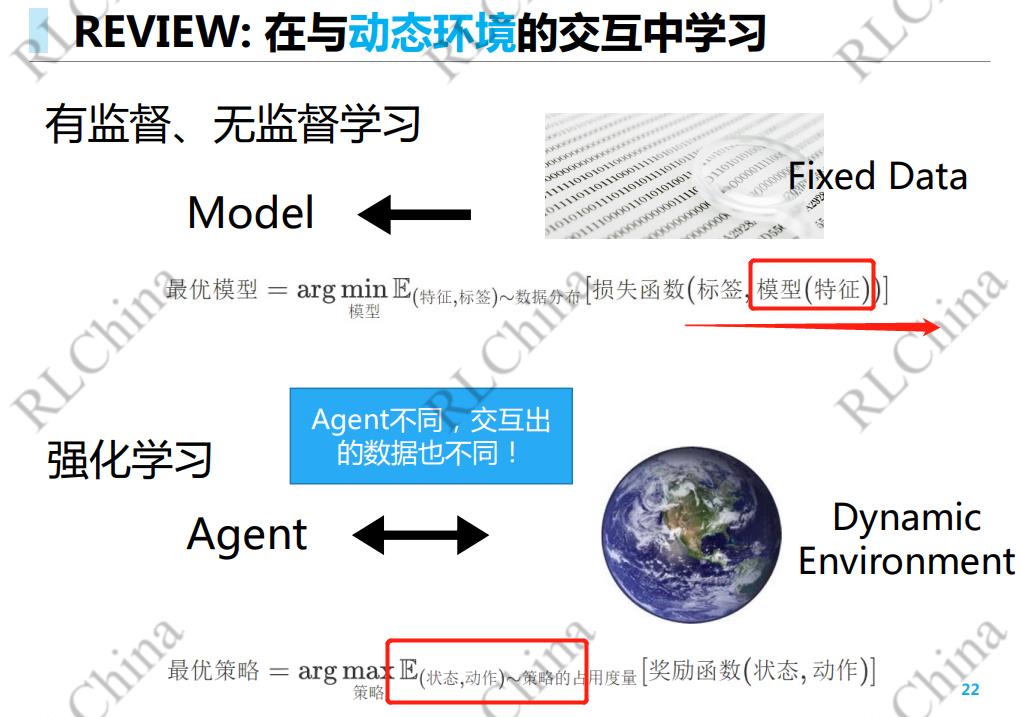
区别刚刚老师讲到了呢,前者是数据分布确定,减少 loss 优化模型参数;而 RL 是优化数据分布找最优策略。也就是一个从固定数据找模型,另一个是优化策略来找最好的数据分布概率。
哦哦好的,这个讲的挺清楚的,谢谢!
-
老师好,请问蒙特卡洛树搜索能否归纳在强化学习的框架中?
-
MC 和 reinforcement 有啥关系吗
-
老师好,在强化学习训练方面,可以设计辅助神经网络来加快训练,减少高估吗?谢谢
-
老师您好,我是一名博士研究生。我心中一直有个怀疑,感觉其实强化学习与监督学习的本质其实都是一样的,只是一个使用奖励来引导学习(虽然交互的数据的分布式变化的,但是环境模型是人给定的,奖励也是人为定义的),一个使用 label 来引导学习。这样做的结果就是强化学习的搜索空间会大很多,但只要算力足够了仍然可以收敛。我想这就是为什么腾讯绝悟,alphastar 等等能用强化学习收敛的直接原因。现在很多言论说 RL 是通向 AGI 的道路,但是是否这样做的话,那么奖励、环境模型的设计事实上比算法模型更加有效,最近看到 deepmind 发的 reward is enough 就很有共鸣,想问问老师对两种学习的本质区别的看法,谢谢老师!
区别刚刚老师讲到了呢,前者是数据分布确定,减少 loss 优化模型参数;而 RL 是优化数据分布找最优策略。也就是一个从固定数据找模型,另一个是优化策略来找最好的数据分布概率。
-
请问老师,奖励函数 R(s,a)为什么不包含下一时刻的状态?
-
老师您好,我看到说策略迭代本质上是牛顿法,所以收敛速度才快,这种说法有理论支撑吗?
-
请问老师,策略提升定理能保证收敛到全局最优,还是只能局部最优?
-
张老师好!请问为什么强化学习目标是最大化累计奖励期望,而不是最大化当前状态的奖励?
-

40 页的策略提示定理因为片面认为某一步提升,其他步不变,就可以实现策略提升,这种提示似乎是最简单绝对的提升。但是忽视了一步降低了,其他步不变,也有可能实现策略提升的情况,就是牺牲短期利益获取更高长期利益的情况。
-
老师您好, 请问刚才所讲的占用度量,是否是说对于一个策略,所有(s,a)的占用度量加起来等于 1/(1-gamma)?两个策略的占用度量相等指的是两者的任意一对(s,a)的占用度量都相等吗?谢谢
-
同步价值迭代和异步价值迭代的适用范围分别是什么?
-
老师您好,我想问一下使用奖励来量化聚类的效果,用强化学习做聚类请问老师有什么好的建议或者文章推荐吗
-
请问占用度量的占用 occupanc 怎么理解?
-
请问 reward 为了保持保持偏序,gama 和的形式的必然性证明,在哪本书里有?
-
在因果推论中如果马尔科夫等价类形成的不同的 DAG 图,其产生的数据分布就是相同的。会不会跟这个占用度量的概念有冲突呢?
-
老师您好,我是一名博士研究生。我对这个 MDP 的结构有个疑问。
1、在选择动作 a 之后是先转移到 S 还是先获得奖励 R 呢,还是说这个不重要?但可能会影响到一个 episode 结束时获得是否要累计最后状态的获得的奖励。 -

老师您好,请问下您认为决策网络会朝着大模型、海量参数的方向发展吗?
- 张老师您好,我是一名准研究生。之前未接触过强化学习,在学习的过程中感觉强化学习很多东西非常抽象,很难理解。希望可以分享一下您当时学习强化学习的经历,能给初学者一些建议。
-
如果一个序列过程的所有状态是确定的,而不是随机的,可以使用 RL 吗?怎么确定什么样的模型可以用 RL 求解呢?
-
老师您好,我是一名博士研究生。我心中一直有个怀疑,感觉其实强化学习与监督学习的本质其实都是一样的,只是一个使用奖励来引导学习(虽然交互的数据的分布式变化的,但是环境模型是人给定的,奖励也是人为定义的),一个使用 label 来引导学习。这样做的结果就是强化学习的搜索空间会大很多,但只要算力足够了仍然可以收敛。我想这就是为什么腾讯绝悟,alphastar 等等能用强化学习收敛的直接原因。现在很多言论说 RL 是通向 AGI 的道路,但是是否这样做的话,那么奖励、环境模型的设计事实上比算法模型更加有效,最近看到 deepmind 发的 reward is enough 就很有共鸣,想问问老师对两种学习的本质区别的看法,谢谢老师!