木棉
这家伙很懒,什么都没留下
评论(3)
请
登录后发表观点
-
 答案很接地气,非常感谢🤗,我太死板了,以为公式不能调整,一直再调整收益函数的取值范围 . 顺便请问一下,RL里面收益函数的设计有没有啥经验或要求?
答案很接地气,非常感谢🤗,我太死板了,以为公式不能调整,一直再调整收益函数的取值范围 . 顺便请问一下,RL里面收益函数的设计有没有啥经验或要求?你是指 Q 函数怎么设计吗?最简单的比如说 tabular Q 就是以表格形式储存Q: \mathcal{S}\times \mathcal{A} \rightarrow q的映射,连续的空间可能会用到深度模型q = MLP(s, a)。 可以根据具体的算法来了解 Q 的设置哦, 比如这里-> http://www.jidiai.cn/algorithm
-
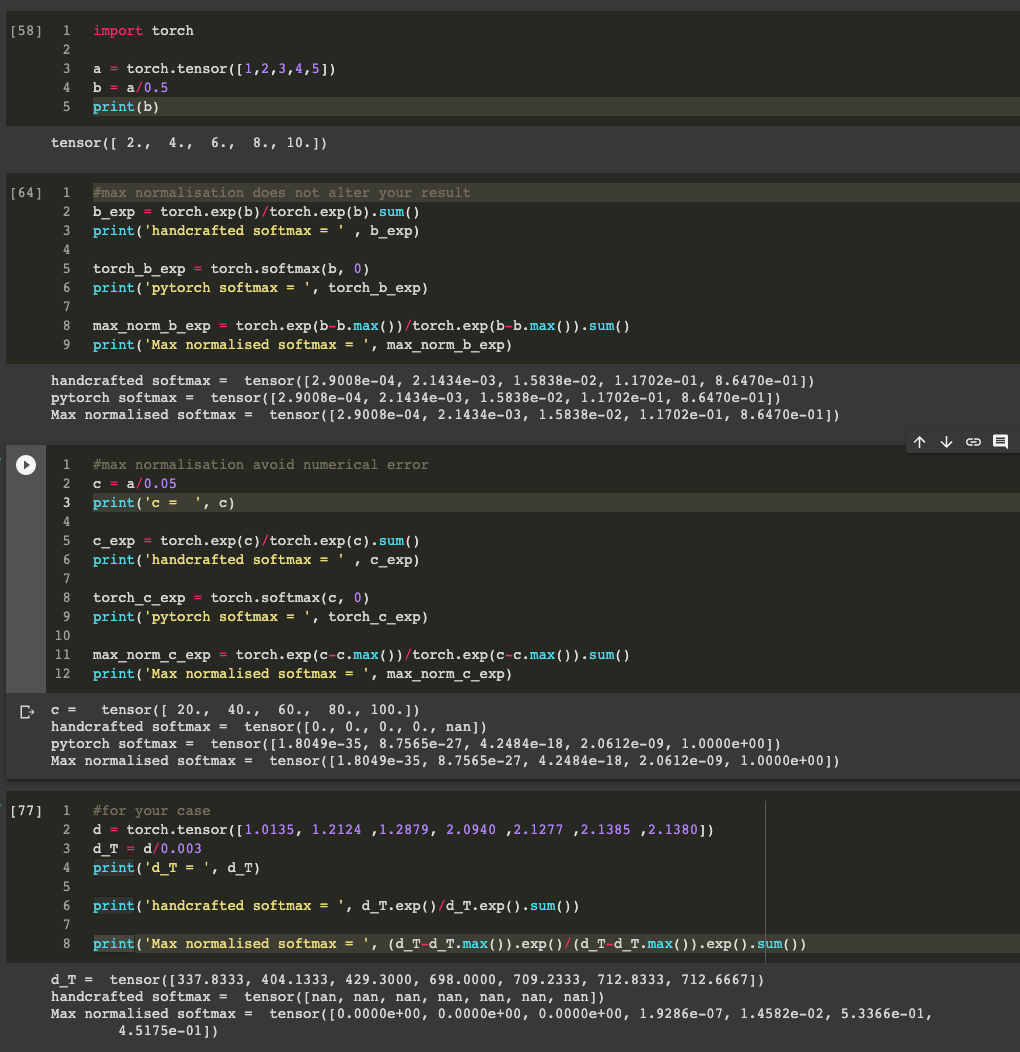
调整 TX 的目的更多的可能是让你的分布变得 hard 或者 soft,如果你单纯是为解决 NaN 的问题的话可以尝试在 exp 之前 clip value (比如 torch.clip()), 或者尝试 max-normalisation:
![]() 答案很接地气,非常感谢🤗,我太死板了,以为公式不能调整,一直再调整收益函数的取值范围 . 顺便请问一下,RL里面收益函数的设计有没有啥经验或要求?
答案很接地气,非常感谢🤗,我太死板了,以为公式不能调整,一直再调整收益函数的取值范围 . 顺便请问一下,RL里面收益函数的设计有没有啥经验或要求? -
调整 TX 的目的更多的可能是让你的分布变得 hard 或者 soft,如果你单纯是为解决 NaN 的问题的话可以尝试在 exp 之前 clip value (比如 torch.clip()), 或者尝试 max-normalisation:
![]()